LinkedIn has reduced the size of link preview images for organic posts, while maintaining larger preview images for sponsored content.
Why it matters. The change aims to encourage more native posting on LinkedIn and could prompt more users and brands to pay for sponsored posts to retain larger link previews.
Why we care. The change incentivizes advertisers to pay to promote posts to get more visibility with larger link previews.
Driving the news. As part of this “feed simplification” update announced months ago, LinkedIn is making preview images significantly smaller for organic posts with third-party links.
Sponsored posts will still display larger preview images from 360 x 640 pixels up to 2430 x 4320 pixels.
The smaller organic previews are meant to “help members stay on LinkedIn and engage with unique commentary.”
What they’re saying. “When an organic post becomes a Sponsored Content ad, the small thumbnail preview image shown in the organic post is converted to an image with a minimum of 360 x 640 pixels and a maximum of 2430 x 4320 pixels,” per LinkedIn.
The other side. Some criticize the move as penalizing professionals who don’t have time for constant original posting and rely on sharing third-party content.
The bottom line. Brands and individuals looking for maximum engagement from shared links on LinkedIn may increasingly need to pay for sponsored posts.
from Search Engine Land https://ift.tt/AZkLunJ
via IFTTT
Google is rolling out changes to comply with new state privacy laws and user opt-out preferences across its ads and analytics products in 2024.
The big picture. Google is adjusting its practices as Florida, Texas, Oregon, Montana and Colorado enact new data privacy regulations this year.
Key updates include:
Restricted Data Processing (RDP) (which is when Google limits how it uses data to only show non-personalized ads) for new state laws:
Google will update its ads terms to enable RDP for these states as their laws take effect.
This allows Google to act as a data processor rather than a controller for partner data while RDP is enabled.
No additional action required if you’ve already accepted Google’s online data protection terms.
Honoring global privacy control opt-outs:
To comply with Colorado’s Universal Opt-Out Mechanism, Google will respect Global Privacy Control signals sent directly from users.
This will disable personalized ad targeting based on things like Customer Match and remarketing lists for opted-out users.
Why we care. This change Google is implementing will help keep advertisers on the right side of the law when it comes to privacy. However, the changes could impact ad targeting efficiency and personalization capabilities as more users opt out.
What they’re saying. Here’s what Google told partners in an email:
“If you’ve already agreed to the online data protection terms, customers [i.e. advertisers] should note that Google can receive Global Privacy Control signals directly from users and will engage RDP mode on their behalf.”
Bottom line. Google is taking steps to help partners comply with tightening data privacy rules, even if it means limiting its own ad targeting.
from Search Engine Land https://ift.tt/XFgdHs7
via IFTTT
Site launches are arguably one of the most risky SEO endeavors. You can go from pure SEO bliss to catastrophe at the flip of a switch.
I’m sure any experienced SEO you ask could tell you a site launch horror story or two; whether it was their own doing due to lack of knowledge/experience or something completely out of their hands.
My hope with today’s article is that you may learn something from some of the lessons I’ve learned launching websites over the past decade. At the very least, perhaps it’ll help prevent one less site launch horror story.
Below are some of the major lessons I’ve learned and aren’t in any particular order of importance.
1. Excluding low-traffic pages from redirects during a site launch is risky
I learned this lesson the hard way when working at an agency years ago.
For whatever reason, at the time, we only redirected the top 500 pages of a site based on traffic, links and overall page authority.
If it was a CMS page (like category pages), those also got redirected.
As for the rest, if we could find a way to mass redirect chunks of them beyond that, we did. If not, we cut it off there.
When managing an ecommerce site with thousands upon thousands of pages, low search traffic to a specific page or set of pages can still add up to hundreds or thousands of visits overall. This can lead to a significant decrease in total traffic after launch.
If you want to avoid any type of traffic loss, make sure you set up a time with your web team in advance to discuss a 301 redirect strategy so that you can redirect the majority, if not all, of your old pages to your new pages.
2. Issues with redirects can cause major technical problems and traffic loss after a site launch
Even the most perfect 301 redirect strategy can go awry.
Not only is it important that you have a good strategy and list, but it’s almost just as important to test that redirects are working properly immediately after launch.
You’ll want to check for things like:
Redirect chains.
Loops.
302 redirects.
To do this, I recommend using Screaming Frog’s list mode feature to audit your redirects by uploading your redirect list and checking the final destination of each URL. I also use a tool called WhereGoes to check for redirect loops and chains. To me, it’s never a bad thing to use more than one tool for testing.
3. Changing the user experience can tank your new site’s traffic for months
I once worked on a furniture site. All kinds of changes were being made – from the overall site design to the navigation, filters and the checkout experience.
Making these changes is not bad. However, without the proper testing, things can go wrong quickly.
After launch, we experienced traffic loss and conversion rate drops. Customers also had issues at the checkout. There were a lot of problems, to say the least.
As time went on, things got slightly better, but I’m not sure they ever fully recovered.
You can expect issues with any launch, but when the conversion rate tanks, that is a major sign of user experience issues. Especially when you roll out changes like navigation updates, different filters and a new design.
This experience highlighted the importance of having a skilled user experience team for a successful site launch. It can make or break your site!
4. Not involving SEO from the beginning is a recipe for disaster
I was initially brought in only to collaborate with an outside agency on the redirect strategy (and some other SEO details) for the furniture company site relaunch I mentioned earlier.
I wasn’t included in site launch meetings. I had no access to wireframes, designs or related materials.
In hindsight, I should have requested more information. I assumed those aspects were being handled.
What I’ve learned since: it’s in your best interest to proactively involve yourself in any area that might impact SEO.
Many people often overlook your work as an SEO. You’re often better off assuming people don’t know what you know than assuming it is being thought about or taken care of because it likely isn’t.
If it is being thought about and being taken care of properly, that’s amazing. You’re one of the lucky few. At least you know you did your due diligence.
Here are things you should be involved in for a site launch:
Strategy meetings
Wireframe / information architecture reviews
Design / UX discussions
Keyword research for new pages
Staging site access and reviews
301 redirect strategy
Post-launch review
You can improve this process more through better cross-team collaboration and communicating the importance of what you do and why you do it.
This can be done through better processes, documentation, training and simply educating other teams. Oftentimes, in SEO, you have to be your own advocate.
Site launches are inherently risky endeavors for SEO, but proper planning and cross-functional collaboration can help you avoid potential pitfalls.
While not an exhaustive guide, learning from the hard-earned lessons outlined here can spare you from common site launch blunders that set SEO efforts back months or even years.
from Search Engine Land https://ift.tt/92Xu8HR
via IFTTT
Google responded to the bad press surrounding its recently rolled out AI Overviews in a new blog post by its new head of Search, Liz Reid. Google explained how AI Overviews work, where the weird AI Overviews came from, the improvements Google made and will continue to make to its AI Overviews.
However, Google said searchers “have higher satisfaction with their search results, and they’re asking longer, more complex questions that they know Google can now help with,” and basically, these AI Overviews are not going anywhere.
As good as featured snippets. Google said the AI Overviews are “highly effective” and based on its internal testing, the AI Overviews “accuracy rate for AI Overviews is on par with featured snippets.” Featured snippets also use AI, Google said numerous times.
No hallucinations. AI Overviews generally don’t hallucinate, Google’s Liz Reid wrote. The AI Overviews don’t “make things up in the ways that other LLM products might,” she added. AI Overviews typically only go wrong when Google “misinterpreting queries, misinterpreting a nuance of language on the web, or not having a lot of great information available,” she wrote.
Why the “odd results.” Google explained that it tested AI Overviews “extensively” before releasing it and was comfortable releasing it. But Google said that people tried to get the AI Overviews to return odd results. “We’ve also seen nonsensical new searches, seemingly aimed at producing erroneous results,” Google wrote.
Also, Google wrote that people faked a lot of the examples, but manipulating screenshots showing fake AI responses. “Those AI Overviews never appeared,” Google said.
Some odd examples did come up, and Google will make improvements in those types of cases. Google will not manually adjust AI Overviews but rather improve the models so they work across many more queries. “we don’t simply “fix” queries one by one, but we work on updates that can help broad sets of queries, including new ones that we haven’t seen yet,” Google wrote.
Google spoke about the “data voids,” which we covered numerous times here. The example, “How many rocks should I eat?” was a query no one has searched for prior and had no real good content on. Google explained, “However, in this case, there is satirical content on this topic … that also happened to be republished on a geological software provider’s website. So when someone put that question into Search, an AI Overview appeared that faithfully linked to one of the only websites that tackled the question.”
Improvements to AI Overviews. Google shared some of the improvements it has made to AI Overviews, explaining it will continue to make improvements going forward. Here is what Google said it has done so far:
Built better detection mechanisms for nonsensical queries that shouldn’t show an AI Overview, and limited the inclusion of satire and humor content.
Updated its systems to limit the use of user-generated content in responses that could offer misleading advice.
Added triggering restrictions for queries where AI Overviews were not proving to be as helpful.
For topics like news and health, Google said it already have strong guardrails in place. For example, Google said it aims to not show AI Overviews for hard news topics, where freshness and factuality are important. In the case of health, Google said it launched additional triggering refinements to enhance our quality protections.
Finally, “We’ll keep improving when and how we show AI Overviews and strengthening our protections, including for edge cases, and we’re very grateful for the ongoing feedback,” Liz Reid ended with.
Why we care. It sounds like AI Overviews are not going anywhere and Google will continue to show them to searchers and roll them out to more countries and users in the future. You can expect them to get better over time, as Google continues to hear feedback and improve its systems.
Until then, I am sure we will find more examples of inaccurate and sometimes humorous AI Overviews, similar to what we saw when featured snippets initially launched.
from Search Engine Land https://ift.tt/2UECa7d
via IFTTT
It’s valuable to discuss this further and offer clarification so we can use what we’ve learned more productively.
After all, these documents are the clearest look at how Google actually considers features of pages that we have had to date.
In this article, I want to attempt to be more explicitly clear, answer common questions, critiques, and concerns and highlight additional actionable findings.
Finally, I want to give you a glimpse into how we will be using this information to do cutting-edge work for our clients. The hope is that we can collectively come up with the best ways to update our best practices based on what we’ve learned.
Reactions to the leak: My thoughts on common criticisms
Let’s start by addressing what people have been saying in response to our findings. I’m not a subtweeter, so this is to all of y’all and I say this with love.
‘We already knew all that’
No, in large part, you did not.
Generally speaking, the SEO community has operated based on a series of best practices derived from research-minded people from the late 1990s and early 2000s.
For instance, we’ve held the page title in such high regard for so long because early search engines were not full-text and only indexed the page titles.
These practices have been reluctantly updated based on information from Google, SEO software companies, and insights from the community. There were numerous gaps that you filled with your own speculation and anecdotal evidence from your experiences.
If you’re more advanced, you capitalized on temporary edge cases and exploits, but you never knew exactly the depth of what Google considers when it computes its rankings.
You also did not know most of its named systems, so you would not have been able to interpret much of what you see in these documents. So, you searched these documents for the things that you do understand and you concluded that you know everything here.
That is the very definition of confirmation bias.
In reality, there are many features in these documents that none of us knew.
Just like the 2006 AOL search data leak and the Yandex leak, there will be value captured from these documents for years to come. Most importantly, you also just got actual confirmation that Google uses features that you might have suspected. There is value in that if only to act as proof when you are trying to get something implemented with your clients.
Finally, we now have a better sense of internal terminology. One way Google spokespeople evade explanation is through language ambiguity. We are now better armed to ask the right questions and stop living on the abstraction layer.
‘We should just focus on customers and not the leak’
We operate in a channel that is considered a black box. Our customers ask us questions that we often respond to with “it depends.”
I’m of the mindset that there is value in having an atomic understanding of what we’re working with so we can explain what it depends on. That helps with building trust and getting buy-in to execute on the work that we do.
Mastering our channel is in service of our focus on our customers.
‘The leak isn’t real’
Skepticism in SEO is healthy. Ultimately, you can decide to believe whatever you want, but here’s the reality of the situation:
Erfan had his Xoogler source authenticate the documentation.
Rand worked through his own authentication process.
I also authenticated the documentation separately through my own network and backchannel resources.
I can say with absolute confidence that the leak is real and has been definitively verified in several ways including through insights from people with deeper access to Google’s systems.
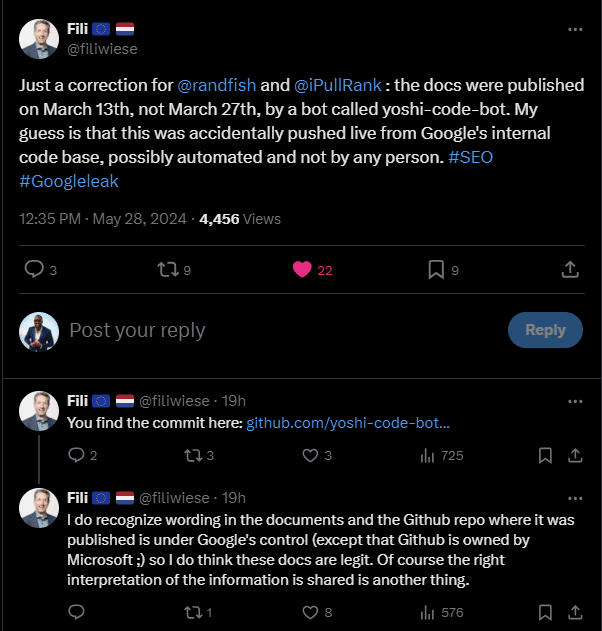
In addition to my own sources, Xoogler Fili Wiese offered his insight on X. Note that I’ve included his call out even though he vaguely sprinkled some doubt on my interpretations without offering any other information. But that’s a Xoogler for you, amiright?
Finally, the documentation references specific internal ranking systems that only Googlers know about. I touched on some of those systems and cross-referenced their functions with detail from a Google engineer’s resume.
I’ll see you on page 2 of the SERPs while I’m having mine medium with cheese, mayo, ketchup and mustard.
“It doesn’t say CTR so it’s not being used”
So, let me get this straight, you think a marvel of modern technology that computes an array of data points across thousands of computers to generate and display results from tens of billions of pages in a quarter of a second that stores both clicks and impressions as features is incapable of performing basic division on the fly?
… OK.
“Be careful with drawing conclusions from this information”
I agree with this. We all have the potential to be wrong in our interpretation here due to the caveats that I highlighted.
To that end, we should take measured approaches in developing and testing hypotheses based on this data.
The conclusions I’ve drawn are based on my research into Google and precedents in Information Retrieval, but like I said it is entirely possible that my conclusions are not absolutely correct.
“The leak is to stop us from talking about AI Overviews”
The documents were discovered in May. Had someone discovered it sooner, it would have been shared sooner.
The timing of AI Overviews has nothing to do with it. Cut it out.
“We don’t know how old it is”
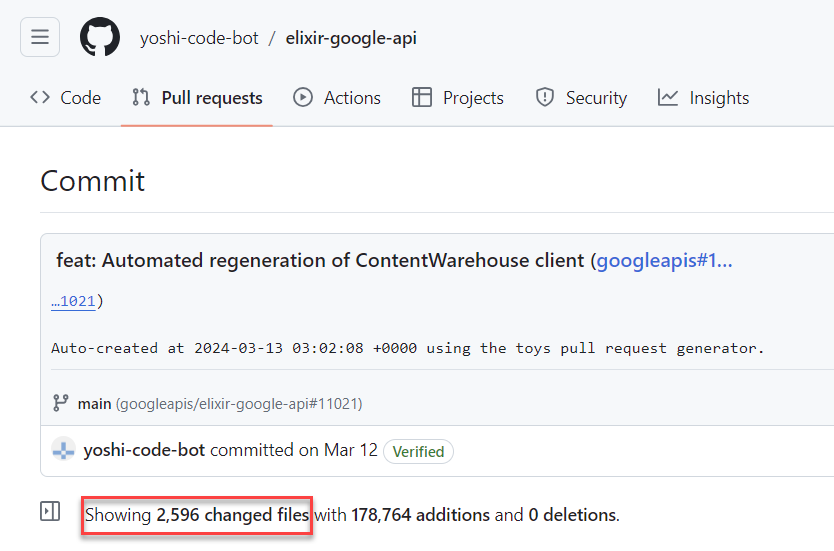
This is immaterial. Based on dates in the files, we know it’s at least newer than August 2023.
We know that commits to the repository happen regularly, presumably as a function of code being updated. We know that much of the docs have not changed in subsequent deployments.
We also know that when this code was deployed, it featured exactly the 2,596 files we have been reviewing and many of those files were not previously in the repository. Unless whoever/whatever did the git push did so with out of date code, this was the latest version at the time.
The documentation has other markers of recency, like references to LLMs and generative features, which suggests that it is at least from the past year.
Either way it has more detail than we have ever gotten before and more than fresh enough for our consideration.
“This all isn’t related to search”
That is correct. I indicated as much in my previous article.
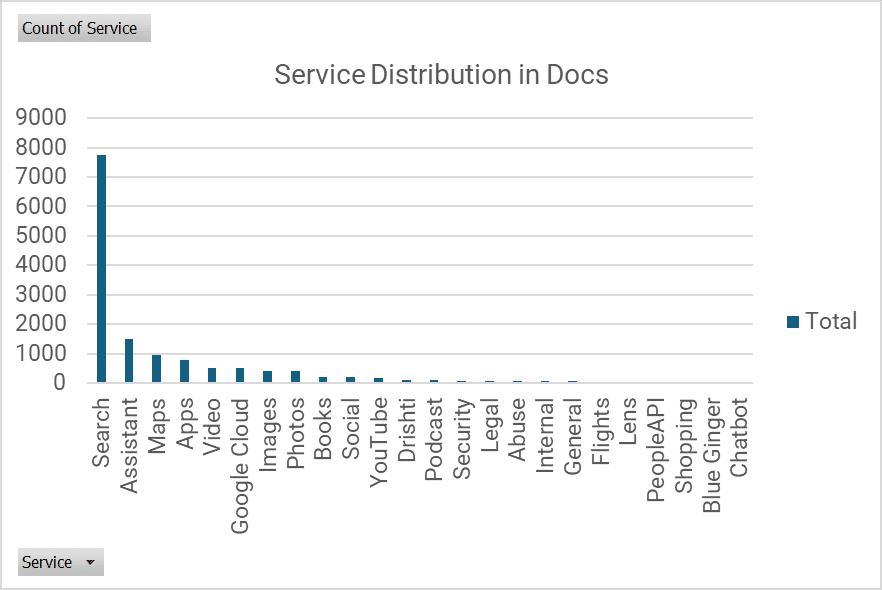
What I did not do was segment the modules into their respective service. I took the time to do that now.
Here’s a quick and dirty classification of the features broadly classified by service based on ModuleName:
Of the 14,000 features, roughly 8,000 are related to Search.
“It’s just a list of variables”
Sure.
It’s a list of variables with descriptions that gives you a sense of the level of granularity Google uses to understand and process the web.
If you care about ranking factors this documentation is Christmas, Hanukkah, Kwanzaa and Festivus.
“It’s a conspiracy! You buried [thing I’m interested in]”
Why would I bury something and then encourage people to go look at the documents themselves and write about their own findings?
Make it make sense.
“This won’t change anything about how I do SEO”
This is a choice and, perhaps, a function of me purposely not being prescriptive with how I presented the findings.
What we’ve learned should at least enhance your approach to SEO strategically in a few meaningful ways and can definitely change it tactically. I’ll discuss that below.
FAQs about the leaked docs
I’ve been asked a lot of questions in the past 48 hours so I think it’s valuable to memorialize the answers here.
What were the most interesting things you found?
It’s all very interesting to me, but here’s a finding that I did not include in the original article:
Google can specify a limit of results per content type.
In other words, they can specify only X number of blog posts or Y number of news articles can appear for a given SERP.
Having a sense of these diversity limits could help us decide which content formats to create when we are selecting keywords to target.
For instance, if we know that the limit is three for blog posts and we don’t think we can outrank any of them, then maybe a video is a more viable format for that keyword.
What should we take away from this leak?
Search has many layers of complexity. Even though we have a broader view into things we don’t know which elements of the ranking systems trigger or why.
We now have more clarity on the signals and their nuances.
I have not dug into that, but there are 23 modules with YouTube prefixes.
Someone should definitely do and interpretation of it.
How does this impact the (_______) space?
The simple answer is, it’s hard to know.
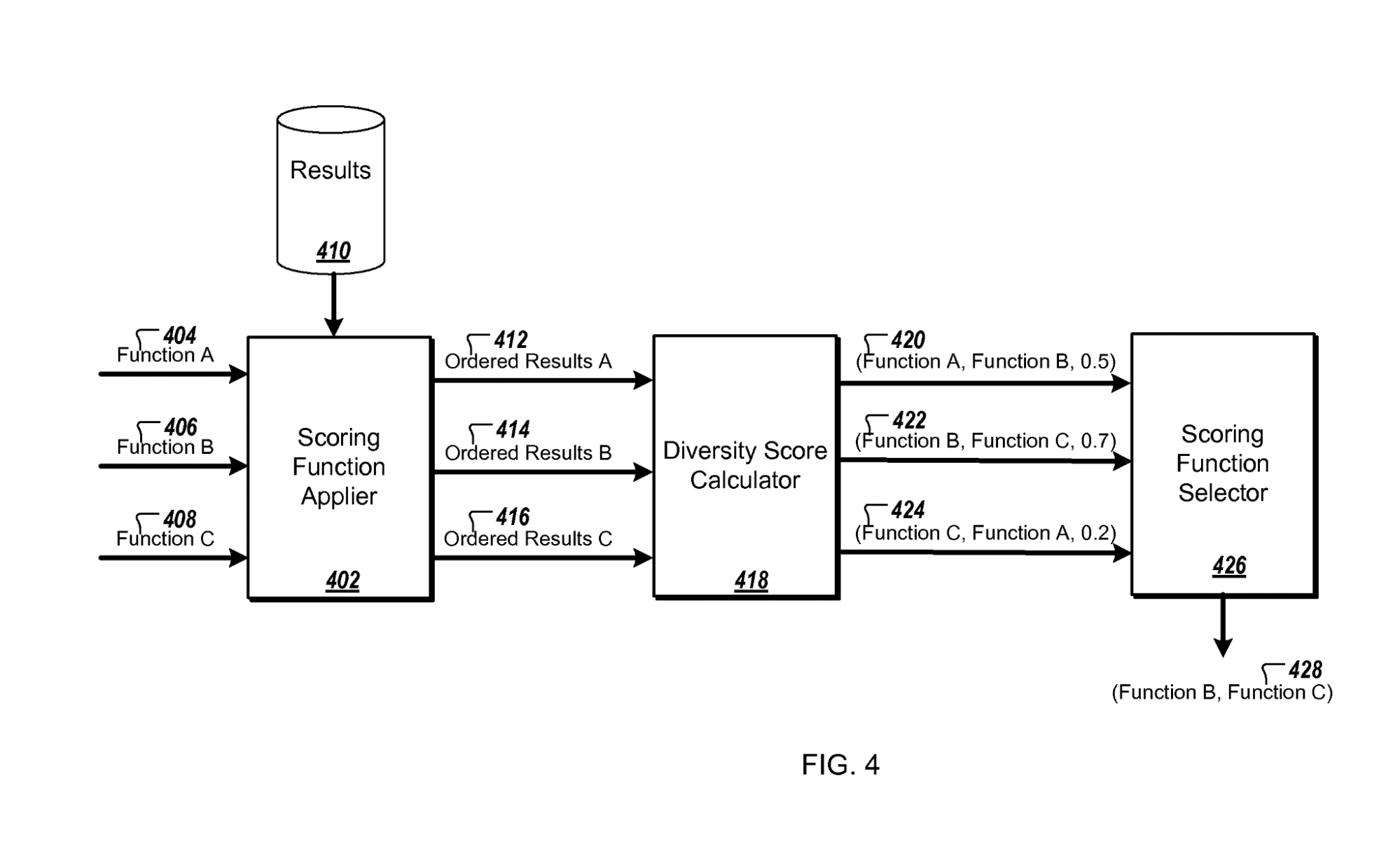
An idea that I want to continue to drill home is that Google’s scoring functions behave differently depending on your query and context. Given the evidence we see in how the SERPs function, there are different ranking systems that activate for different verticals.
To illustrate this point, the Framework for evaluating web search scoring functions patent shows that Google has the capability to run multiple scoring functions simultaneously and decide which result set to use once the data is returned.
While we have many of the features that Google is storing, we do not have enough information about the downstream processes to know exactly what will happen for any given space.
That said, there are some indicators of how Google accounts for some spaces like Travel.
The QualityTravelGoodSitesData module has features that identify and score travel sites, presumably to give them a Boost over non-official sites.
Do you really think Google is purposely torching small sites?
Signals like links and clicks inherently support big brands. Those sites naturally attract more links and users are more compelled to click on brands they recognize.
Big brands can also afford agencies like mine and more sophisticated tooling for content engineering so they demonstrate better relevance signals.
It’s a self-fulfilling prophecy and it becomes increasingly difficult for small sites to compete in organic search.
If the sites in question would be considered “small personal sites” then Google should give them a fighting chance with a Boost that offsets the unfair advantage big brands have.
Do you think Googlers are bad people?
I don’t.
I think they generally are well-meaning folks that do the hard job of supporting many people based on a product that they have little influence over and is difficult to explain.
They also work in a public multinational organization with many constraints. The information disparity creates a power dynamic between them and the SEO community.
Googlers could, however, dramatically improve their reputations and credibility among marketers and journalists by saying “no comment” more often rather than providing misleading, patronizing or belittling responses like the one they made about this leak.
Although it’s worth noting that the PR respondent Davis Thompson has been doing comms for Search for just the last two months and I’m sure he is exhausted.
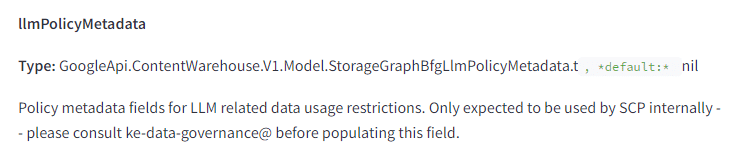
I did find a few policy features for LLMs. This suggests that Google determines what content can or cannot be used from the Knowledge Graph with LLMs.
Is there anything related to generative AI?
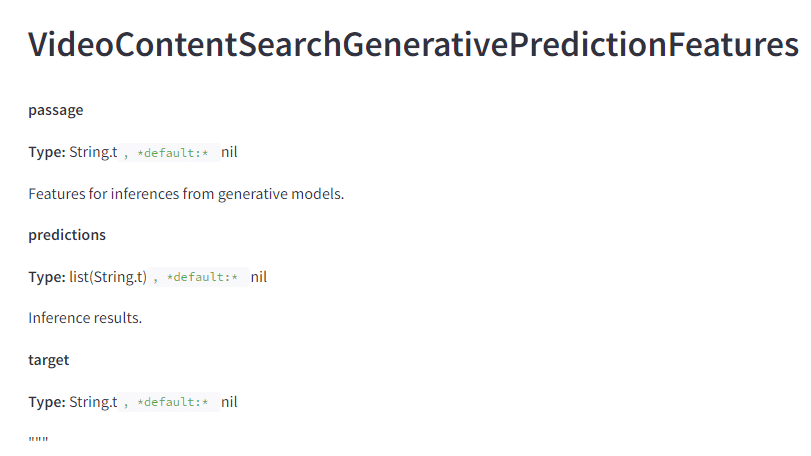
There is something related to video content. Based on the write-ups associated with the attributes, I suspect that they use LLMs to predict the topics of videos.
New discoveries from the leak
Some conversations I’ve had and observed over the past two days has helped me recontextualize my findings – and also dig for more things in the documentation.
Baby Panda is not HCU
Someone with knowledge of Google’s internal systems was able to answer that the Baby Panda references an older system and is not the Helpful Content Update.
I, however, stand by my hypothesis that HCU exhibits similar properties to Panda and it likely requires similar features to improve for recovery.
A worthwhile experiment would be trying to recover traffic to a site hit by HCU by systematically improving click signals and links to see if it works. If someone with a site that’s been struck wants to volunteer as tribute, I have a hypothesis that I’d like to test on how you can recover.
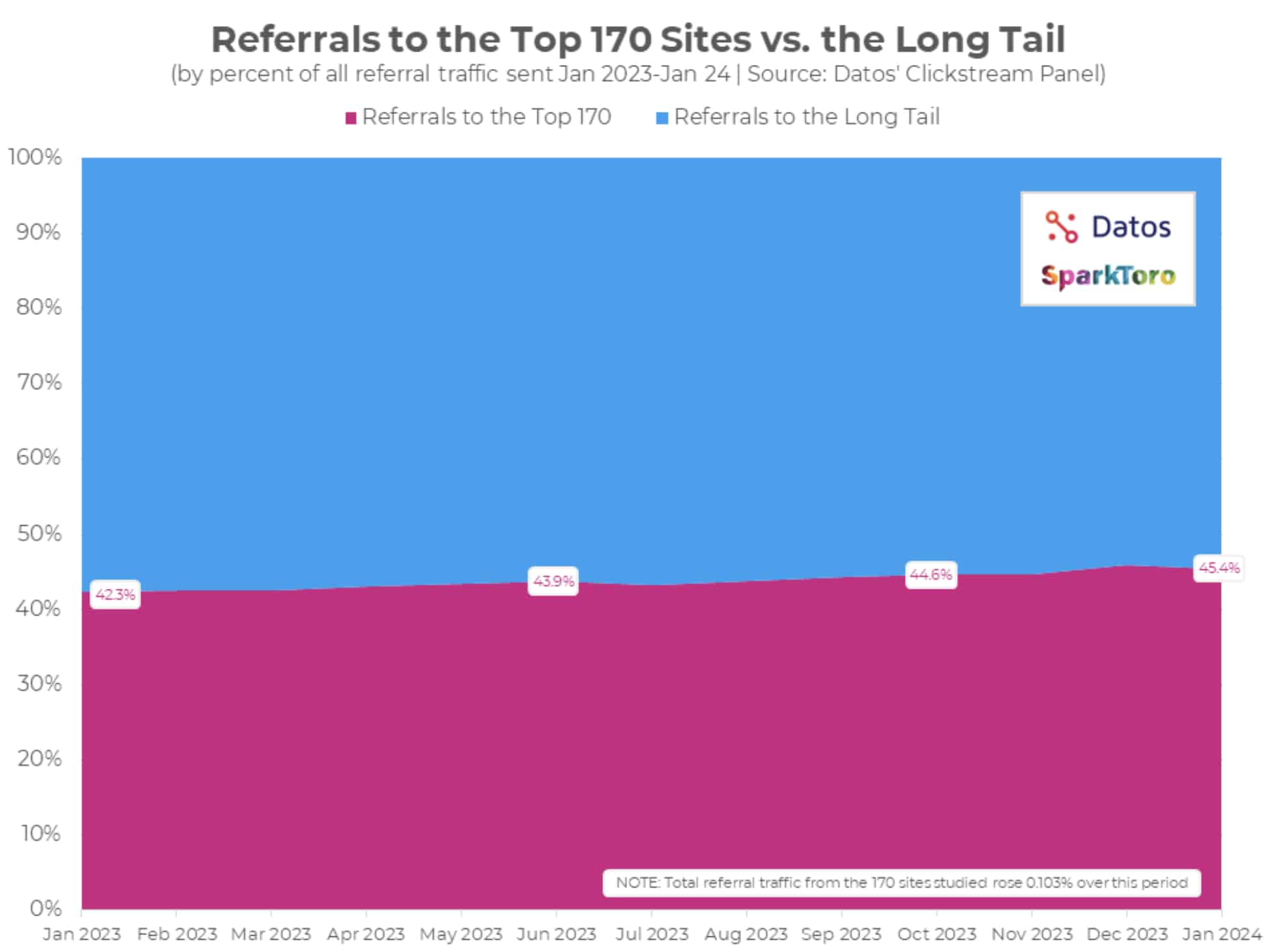
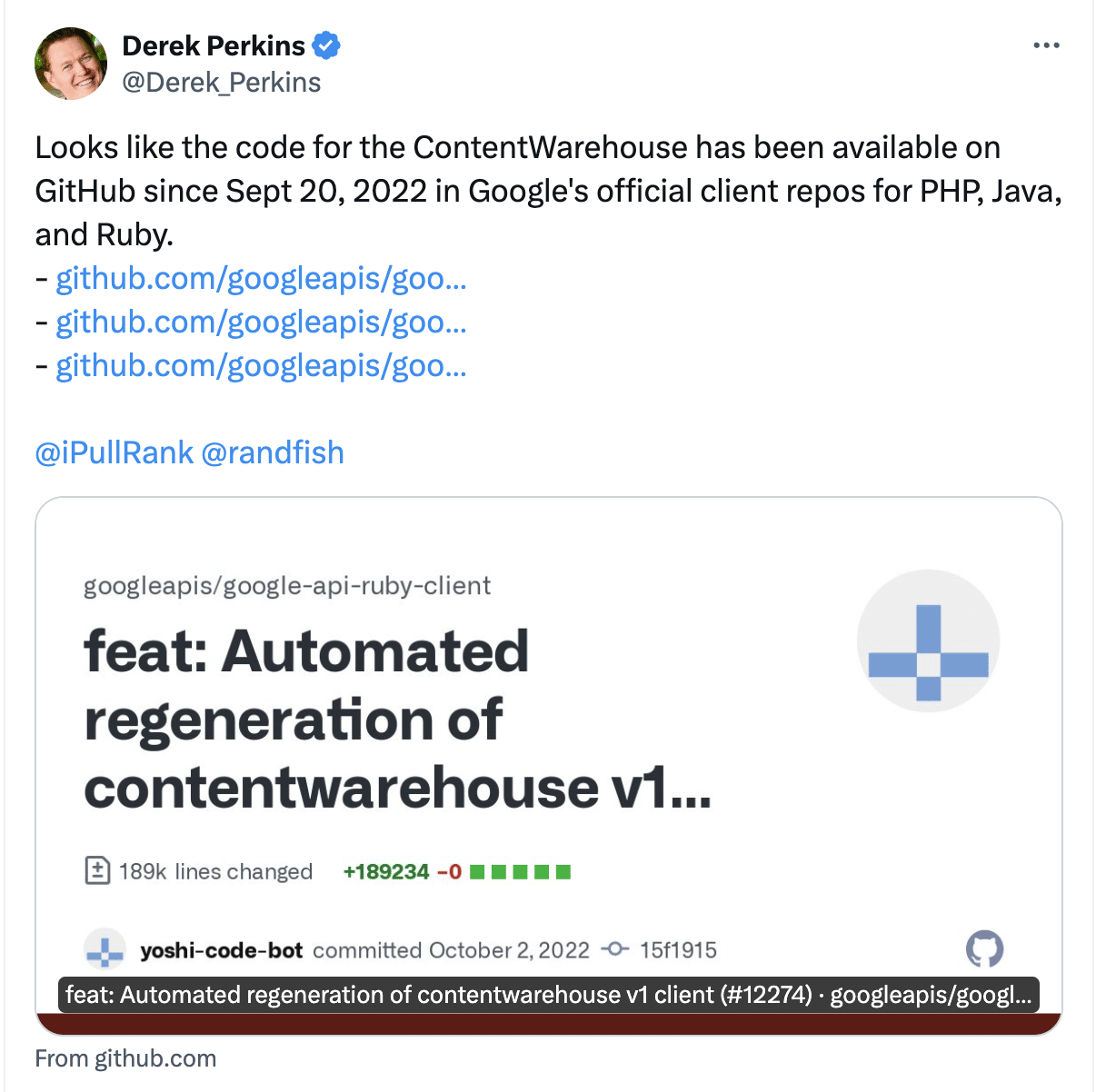
The leaks technically go back two years
Derek Perkins and @SemanticEntity brought to my attention on Twitter that the leaks have been available across languages in Google’s client libraries for Java, Ruby, and PHP.
The difference with those is that there is very limited documentation in the code.
There is a content effort score maybe for generative AI content
Google is attempting to determine the amount of effort employed when creating content. Based on the definition, we don’t know if all content is scored by this way by an LLM or if it is just content that they suspect is built using generative AI.
Nevertheless, this is a measure you can improve through content engineering.
The significance of page updates is measured
The significance of a page update impacts how often a page is crawled and potentially indexed. Previously, you could simply change the dates on your page and it signaled freshness to Google, but this feature suggests that Google expects more significant updates to the page.
Pages are protected based on earlier links in Penguin
According to the description of this feature, Penguin had pages that were considered protected based on the history of their link profile.
This, combined with the link velocity signals, could explain why Google is adamant that negative SEO attacks with links are ineffective.
Toxic backlinks are indeed a thing
We’ve heard that “toxic backlinks” are a concept that simply used to sell SEO software. Yet there is a badbacklinksPenalized feature associated with documents.
There’s a blog copycat score
In the blog BlogPerDocData module there is a copycat score without a definition, but is tied to the docQualityScore.
My assumption is that it is a measure of duplication specifically for blog posts.
Mentions matter a lot
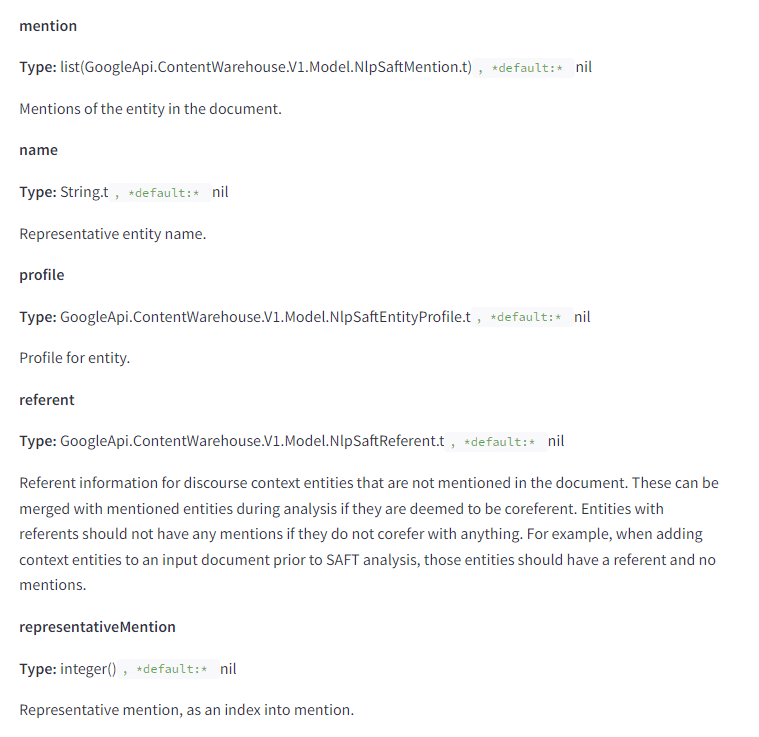
Although I have not come across anything to suggest mentions are treated as links, there are lot of mentions of mentions as they relate to entities.
Googlebot’s fetching mechanism is capable of more than just GET requests.
The documentation indicates that it can do POST, PUT, or PATCH requests as well.
The team previously talked about POST requests, but it the other two HTTP verbs have not been previously revealed. If you see some anomalous requests in your logs, this may be why.
Specific measures of ‘effort’ for UGC
We’ve long believed that leveraging UGC is a scalable way to get more content onto pages and improve their relevance and freshness.
This ugcDiscussionEffortScore suggests that Google is measuring the quality of that content separately from the core content.
When we work with UGC-driven marketplaces and discussion sites, we do a lot of content strategy work related to prompting users to say certain things. That, combined with heavy moderation of the content, should be fundamental to improving the visibility and performance of those sites.
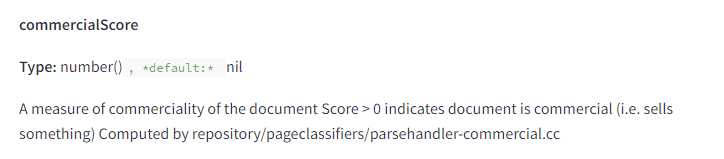
Google detects how commercial a page is
We know that intent is a heavy component of Search, but we only have measures of this on the keyword side of the equation.
Google scores documents this way as well and this can be used to stop a page from being considered for a query with informational intent.
We’ve worked with clients who actively experimented with consolidating informational and transactional page content, with the goal of improving visibility for both types of terms. This worked to varying degrees, but it’s interesting to see the score effectively considered a binary based on this description.
Cool things I’ve seen people do with the leaked docs
I’m pretty excited to see how the documentation is reverberating across the space.
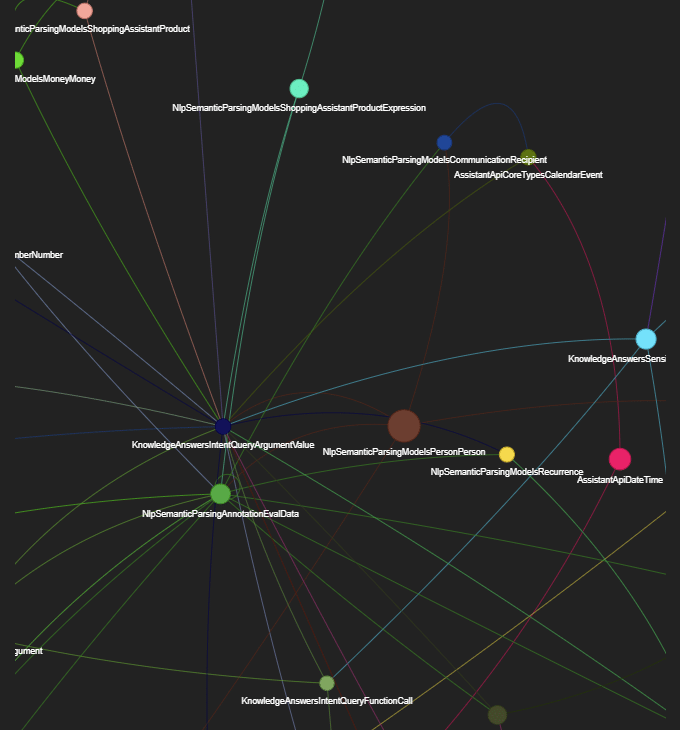
Natzir’s Google’s Ranking Features Modules Relations: Natzir builds a network graph visualization tool in Streamlit that shows the relationships between modules.
WordLifti’s Google Leak Reporting Tool: Andrea Volpini built a Streamlit app that lets you ask custom questions about the documents to get a report.
Direction on how to move forward in SEO
The power is in the crowd and the SEO community is a global team.
I don’t expect us to all agree on everything I’ve reviewed and discovered, but we are at our best when we build on our collective expertise.
Here are some things that I think are worth doing.
How to read the documents
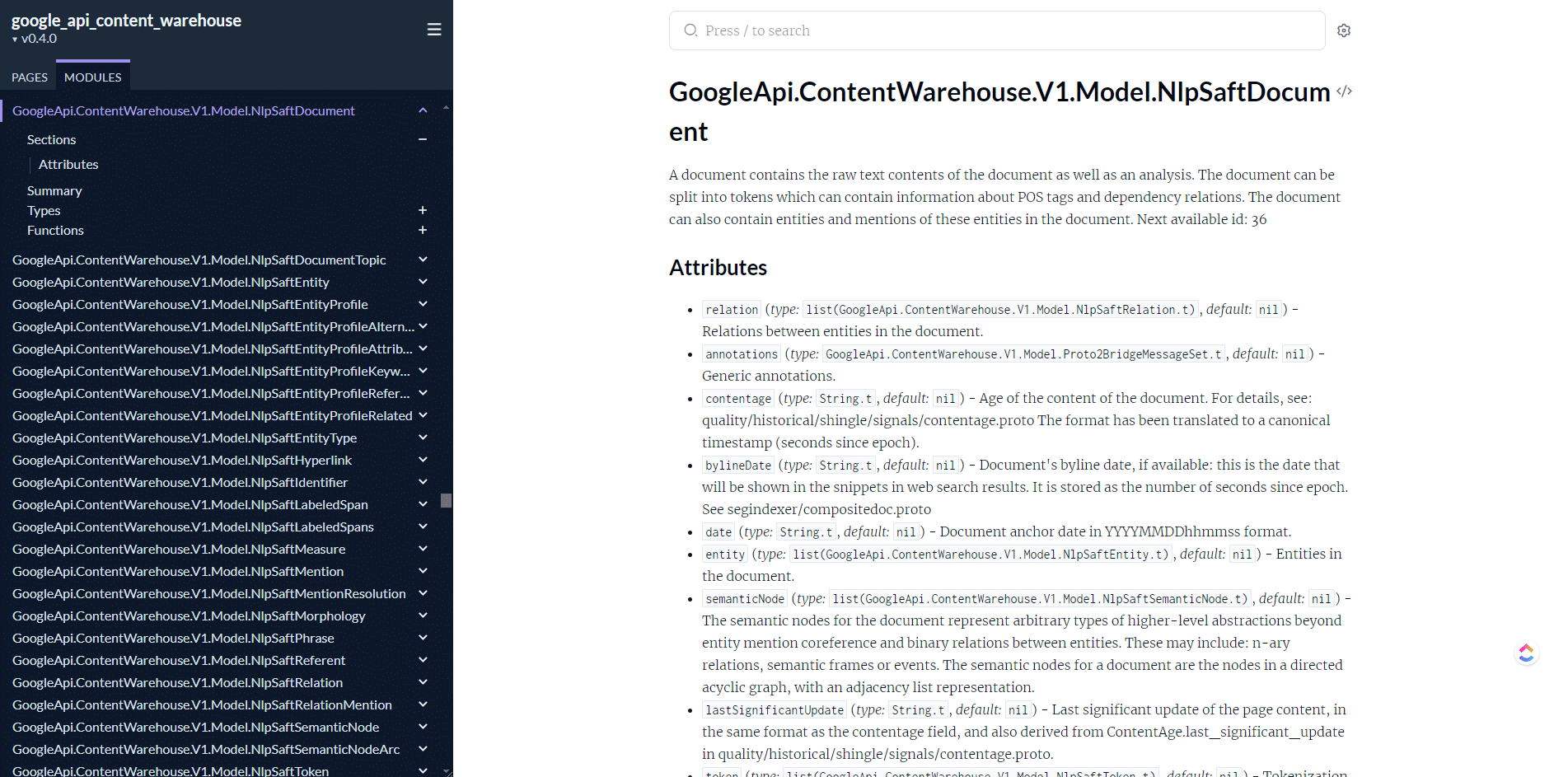
If you haven’t had the chance to dig into the documentation on HexDocs or you’ve tried and don’t know here to start, worry not, I’ve got you covered.
Start fromthe root: This features listings of all the modules with some descriptions. In some cases attributes from the module are being displayed.
Make sure you’re looking at the right version: v0.5.0 Is the patched version The versions prior to that have docs we’ve been discussing.
Scroll down until you find a module that sounds interesting to you: Look through the names and click things that sound interesting. I focused on elements related to search, but you be interested in Assistant, YouTube, etc.
Read through the attributes: As you read through the descriptions of features take note of other features the are referenced in them.
Search: Use that perform searches for those terms in the docs
Repeat until you’re done: Go back to step 1. As you learn more you’ll find other things you want to search and you’ll realize certain strings might mean there are other modules that interest you.
Share your findings: If you find something cool, share it on social or write about it. I’m happy to help you amplify.
One thing that annoys me about HexDocs is how the left sidebar covers most of the names of the modules. This makes it difficult to know what you’re navigating to.
If you don’t want to mess with the CSS, I’ve made a simple Chrome extension that you can install to make the sidebar bigger.
How your approach to SEO should change strategically
Here are some strategic things that you should more seriously consider as part of your SEO efforts.
If you are already doing all these things, you were right, you do know everything, and I salute you.
SEO and UX need to work more closely together
With NavBoost, Google is valuing clicks one of the most important features, but we need to understand what session success means. A search that yields a click on a result where the user does not perform another search can be a success even if they did not spend a lot of time on the site. That can indicate that the user found what they were looking for. Naturally, a search that yields a click and a user spends 5 minutes on a page before coming back to Google is also a success. We need to create more successful sessions.
SEO is about driving people to the page, UX is about getting them to do what you want on the page. We need to pay closer attention to how components are structured and surfaced to get people to the content that they are explicitly looking for and give them a reason to stay on the site. It’s not enough to hide what I’m looking for after a story about your grandma’s history of making apple pies with hatchets or whatever these recipe sites are doing. Rather it should be more about here’s the exact information clearly displayed and enticing the user to remain on the page with something additionally compelling.
Pay more attention to click metrics
We look at the Search Analytics data as outcomes when Google’s ranking systems look at them as diagnostic features. If you rank highly and you have a ton of impressions and no clicks (aside from when SiteLinks throws the numbers off) you likely have a problem. What we are definitively learning is that there is a threshold of expectation for performance based on position. When you fall below that threshold you can lose that position.
Content needs to be more focused
We’ve learned, definitively, that Google uses vector embeddings to determine how far off given a page is from the rest of what you talk about. This indicates that it will be challenging to go far into upper funnel content successfully without a structured expansion or without authors that have demonstrated expertise in that subject area. Encourage your authors to cultivate expertise in what they publish across the web and treat their bylines like the gold standard that it is.
SEO should always be experiment-driven
Due to the variability of the ranking systems, you cannot take best practices at face value for every space. You need to test and learn and build expertmentation into every SEO program. Large sites leveraging products like SEO split testing tool Searchpilot are already on the right track, but even small sites should be testing how they structure and position their content and metadata to encourage stronger click metrics. In other words we need to be actively testing the SERP not just testing the site.
Pay attention to what happens after they leave your site
We now have verification that Google is using data from Chrome as part of the search experience. There is value in reviewing the clickstream data that SimilarWeb and Semrush .Trends provide to see where people are going next and how you can give them that information without them leaving you.
Build keyword and content strategy around SERP format diversity
With Google potentially limiting the number of pages of a certain content types ranking in the SERP, you should be checking for this in the SERPs as part of your keyword research. Don’t align formats with keywords if there’s no reasonable possibility of you ranking.
How your approach to SEO should change tactically
Tactically, here are some things you can consider doing differently. Shout out to Rand because a couple of these ideas are his.
Page titles can be as long as you want
We now have further evidence that indicates the 60-70 character limit is a myth. In my own experience we have experimented with appending more keyword-driven elements to the title and it has yielded more clicks because Google has more to choose from when it rewrites the title.
Use fewer authors on more content
Rather than using an array of freelance authors you should work with fewer that are more focused on subject matter expertise and also write for other publications.
Focus on link relevance from sites with traffic
We’ve learned that link value is higher from pages that prioritized higher in the index. Pages that get more clicks are pages that are likely to appear in Google’s flash memory. We’ve also learned that Google is valuing relevance very highly. We need to stop going after link volume and solely focus on relevance.
Default to originality instead of long form
We now know originality is measured in multiple ways and can yield a boost in performance. Some queries simply don’t require a 5000 word blog post (I know I know). Focus on originality and layer more information in your updates as competitors begin to copy you.
Make sure all dates associated with a page are consistent
It’s common for dates in schema to be out of sync with dates on the page and dates in the XML sitemap. All of these need to be synced to ensure Google has the best understanding of how hold the content is. As you are refreshing your decaying content make sure every date is aligned so Google gets a consistent signal.
Use old domains with extreme care
If you’re looking to use an old domain, it’s not enough to buy it and slap your new content on its old URLs. You need to take a structured approach to updating the content to phase out what Google has in its long term memory. You may even want to avoid their being a transfer of ownership in registrars until you’ve systematically established the new content.
Make gold standard documents
We now have evidence that quality raters are doing feature engineering for Google engineers to train their classifiers. You want to create content that quality raters would score as high quality so your content has a small influence over what happens in the next core update.
Bottom line
It’s short-sighted to say nothing should change. Really, I think it’s time for us to truly reconsider our best practices based on this information.
Let’s keep what works and dump what’s not valuable. Because, I tell you what, there’s no text to code ratio in these documents, but several of your SEO tools will tell your site is falling apart because of it.
How Google can repair its relationship with the SEO community
A lot of people have asked me how can we repair our relationship with Google moving forward.
I would prefer that we get back to a more productive space for the betterment of the web. After all we are aligned in our goals of making search better.
I don’t know that I have a complete solution, but I think an apology and owning their role in misdirection would be a good start. I have a few other ideas that we should consider.
Develop a working relationships with us: On the advertising side, Google wines and dines its clients. I understand that they don’t want to show any sort of favoritism on the organic side, but Google needs to be better about developing actual relationships with the SEO community. Perhaps a structured program with OKRs that is similar to how other platforms treat their influencers makes sense. Right now things are pretty ad hoc where certain people get invited to events like I/O or to secret meeting rooms during the (now-defunct) Google Dance.
Bring back the annual Google Dance: Hire Lily Ray to dj and make it about celebrating annual OKRs that we have achieved through our partnership.
Work together on more content: The bidirectional relationships that people like Martin Splitt have cultivated through his various video series are strong contributions where Google and the SEO community have come together to make things better. We need more of that.
We want to hear from the engineers more. Personally, I’ve gotten the most value out of hearing directly from search engineers. Paul Haahr’s presentation at SMX West 2016 lives rent-free in my head and I still refer back to videos from the 2019 Search Central Live Conference in Mountain View regularly. I think we’d all benefit from hearing directly from the source.
Everybody keep up the good work
I’ve seen some fantastic things come out of the SEO community in the past 48 hours.
I’m energized by the fervor with which everyone has consumed this material and offered their takes – even when I don’t agree with them. This type of discourse is healthy and what makes our industry special.
I encourage everyone to keep going. We’ve been training our whole careers for this moment.
from Search Engine Land https://ift.tt/Zpc5wfW
via IFTTT
Google officially rolled out the requirement for Consent Mode v2 for Google properties in the European Economic Area (EEA) to ensure its properties complied with the Digital Markets Act (DMA) in March.
ad_user_data, which sets consent for sending user data related to advertising to Google.
ad_personalization, which sets consent for personalized advertising.
This launch caused a frenzy among PPC marketers to ensure compliance before the deadline.
However, a significant number of advertisers have not adopted consent mode, and their ad accounts are at risk of penalization.
Below are four ways to check your current Google consent mode configuration.
1. Check your consent mode configuration in Google Ads
The first and simplest place to start your checks is within Google Ads itself. Within your ad account, navigate to Tools and Settings > Measurement > Conversions > Diagnostics.
If consent mode is active, under Diagnostics, you will see the following widget:
What this tells you is that Google is:
Reading and recording consent statuses for users of your website.
Adjusting its tracking tags behavior based on the consent statuses it reads.
However, it doesn’t tell you whether the correct statuses are being passed.
Thus, further checks and tests are required.
Configuring consent mode via Google Ads
If the first step did not show you a consent mode active widget, then there is work to be done to get the consent mode setup.
Google has some direct integrations that you can access within your Google Ads account:
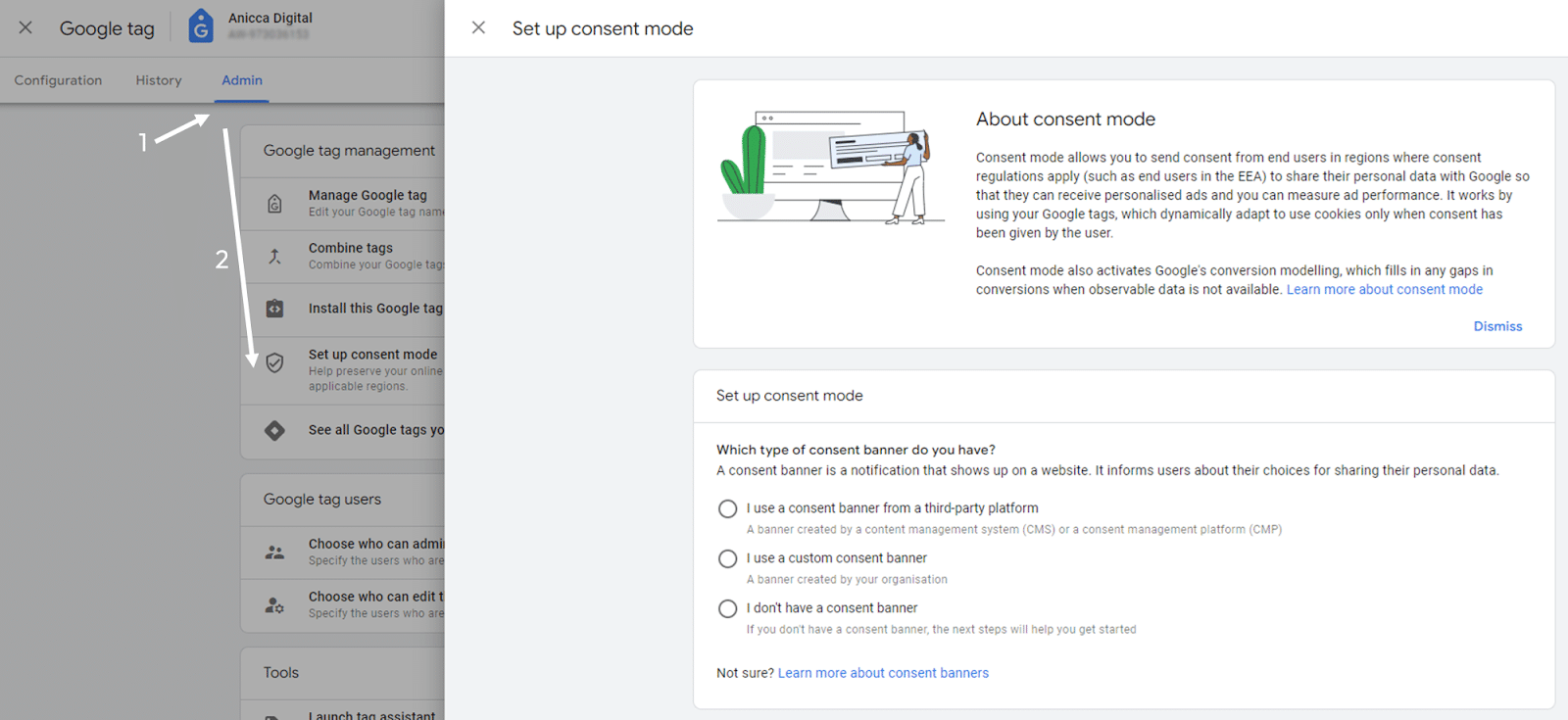
Navigate to Tools and Settings > Setup > Data Manager > Google tag > Manage > Admin.
Under Google Tag Management, click Set up consent mode.
Then choose your banner type and follow the steps
Once you select either your web platform or CMP (consent management platform), it will provide step-by-step instructions on how to set up consent mode.
If you don’t yet have a consent banner, it will also walk you through how to get started.
2. Checking consent status in Google Analytics 4
Like Google Ads, Google also released a feature within GA4 to check consent status.
Again, this lets you check if Google can read and record the consent choices made by users on your website.
To use this feature, follow these steps:
Navigate to your GA4 account.
Select Admin.
Under Data collection and modification, select Data streams.
Select your website data stream.
Click on the Consent settings drop-down.
The consent settings status in GA4 has three parts. It tells you whether measurement and personalization consent signals are active and allows you to verify how Google shares data between its services.
3. Checking consent configuration of tags in Google Tag Manager
Google released a feature in Google Tag Manager (GTM) to aid marketers in ensuring that the correct consent settings are applied to tags deployed through GTM.
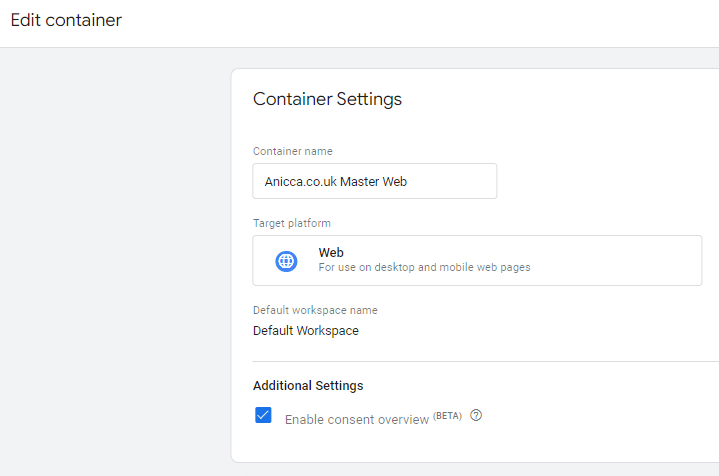
The first thing you need to do is enable the consent overview setting in your GTM account:
Select your container, then click Admin > Container Settings.
Under Additional Settings, check the box to enable consent overview.
Once the setting is enabled, you can navigate back to your workspace and use it to check what consent settings have been applied to each tag.
To find this, you will need to switch from overview to tags, and then next to the blue New button, you will see a shield icon.
Once clicked, it will show you each tag in the account and whether consent settings have been configured. It also identifies any built-in consent settings within a tag. Google tags, for example, all have built-in consent within GTM.
4. Check consent status changes with Google Tag Assistant
You can use Google Tag Assistant to check what statuses are being passed and updated as users move through the website and interact with your cookie consent banner.
There are two places that you can run these checks:
Preview mode in GTM offers additional benefits. It allows you to see which tags are firing at each triggered event. This helps you understand whether the tags are reading the correct consent choices and whether they are firing without any consent choices.
To check the consent updates on the page through both methods, input your URL so it loads in debug mode.
On the left-side navigation, you will see all the events that fire in Tag Assistant. You can click through each event and toggle your output between Tags and Consent to see what consent choices have been made and which tags fired.
The consent statuses will look similar to the screenshot below:
You will see the default status. This is usually denied for everything other than essential cookies required for website functionality.
Depending on which event you select, you will see the on-page update and current state.
If the ad cookies were denied, you would not want your advertising platform tags to fire and drop cookies when you toggle back to tags.
One point to note is that Google tags will always appear as firing in preview mode as their consent settings are built in, and the tags adjust their behavior automatically.
Verify your Google consent mode configuration now
Consent mode will be a crucial element moving forward in any comprehensive tracking setup and ensuring your business is in line with regulations.
To avoid any ad account penalizations or data issues, you will want to ensure that you have consent mode enabled and that it is also done correctly.
From fireside chats to expert-led sessions featuring digital leaders who are blazing a trail in the world of omnichannel marketing, this year’s Emarsys Omnichannel and AI Masterclass is packed full of insights that will leave you buzzing with new ideas.
In this article, we’re going to take a look at three key sessions from the likes of Home Depot, Colgate-Palmolive and Kellanova that you won’t want to miss. Let’s dive in.
More than commerce: How CPG brands are building DTC engagement
Speakers:
Don Brett, Podcast Host, CPG View
Jamie Schwab, VP Global Digital Commerce, Colgate-Palmolive
Jamie Decker, VP e-Commerce, Del Monte
Diana Macia, Director, Global Omnichannel Capabilities, Kellanova (Kellog’s)
What’s in store:
Driven by the modern consumers’ demand for convenience and internal pressures to build brand affinity, the last few years have seen a stampede of consumer products brands opening up direct-to-consumer offerings.
However, with multiple channels in play, the fast-moving world of e-commerce comes with its own set of challenges. Join Don Brett, CPG View Podcast host and an esteemed panel of CPG guests as they discuss:
The importance of a first-party data strategy in 2024.
What value exchanges are being created across the customer journey.
How brands are balancing personalization with consumer trust.
AI’s role across this whole ecosystem and its new applications.
How Home Depot engineers online experiences that ‘Get More Done’ during peak seasons
Speakers:
Mauricio Gonzalez, DFC Logistic Solutions Design Coordinator, Home Depot
Uncompromising quality and supportive staff make Home Depot a one-stop-shop for all things DIY. Now, it’s taking this to the next level, with a brand transformation that delivers an unrivaled customer experience that delivers what customers need, exactly when they need it.
In this session, Home Depot’s Online Experience Department Head shares:
Home Depot’s journey to omnichannel marketing mastery, detailing their transformation from in-store to online.
Key insights into how they prepare for Black Friday, their biggest sales event of the year.
How Replacements, Ltd. plates up traditional and digital marketing to serve a broad demographic
Kara Lewis, Lead Client Strategy Manager, Attentive
What’s in store:
With a 40-year legacy and a mastercraft service that replaces precious pieces of china, it shouldn’t come as a surprise that Replacements Ltd. attracts a more “senior” demographic. However, as they’ve worked to attract younger customers, they’ve seen an interesting change – more of their older customers are engaging on newer marketing channels.
The result? A fascinating intersection between traditional and transformative marketing that requires a unique strategy. Join Replacements Ltd.’s E-commerce Marketing Manager and Attentive’s Lead Client Strategy Manager, as they discuss how Replacements Ltd. is using cutting-edge marketing tech and customer data to bridge the gap between old and new.
These are just some of the brands and sessions that are now confirmed for the AI & Omnichannel Masterclass hosted by Emarsys.
Sign up now to get access to all sessions, live and online from 12 to 13 June.
from Search Engine Land https://ift.tt/v2CzZ4M
via IFTTT